---
title: "Einführung in die Hypothesentests"
subtitle: "Vom Verdacht zur statistisch abgesicherten Entscheidung"
author:
- name: "Markus Geuss"
affiliation: "Fernfachhochschule Schweiz"
title-block-banner: ./images/ffhs-farbwelt-verlauf_01.jpg
lang: de
language:
de:
author-meta-affiliation: "Hochschule"
format:
html:
logo: ./images/FFHS_Logo.png
include-in-header:
text: |
<style>
.title { color: white !important; }
.subtitle { color: white !important; }
.quarto-title-banner .quarto-title {
padding-left: 160px;
}
</style>
<script>
document.addEventListener('DOMContentLoaded', function () {
var banner = document.querySelector('.quarto-title-banner');
if (banner) {
banner.style.position = 'relative';
var logo = document.createElement('img');
logo.src = './images/FFHS_Logo.png';
logo.style.cssText = [
'position: absolute',
'left: 0px',
'top: 50%',
'transform: translateY(-50%)',
'height: 75px',
'width: auto',
'z-index: 10',
'filter: brightness(0) invert(1)'
].join(';');
banner.insertBefore(logo, banner.firstChild);
}
});
</script>
theme: cosmo
toc: true
toc-title: "Inhaltsverzeichnis"
toc-depth: 3
toc-location: right
code-fold: true
code-tools: true
self-contained: false
execute:
warning: false
message: false
editor:
markdown:
wrap: sentence
---
```{r}
#| label: setup
#| include: false
library(tidyverse)
library(patchwork)
# Reproduzierbarer Datensatz: API-Antwortzeiten (ms) eines REST-Dienstes
# Szenario: 40 gemessene Antwortzeiten nach einem Architektur-Refactoring
set.seed(42)
n <- 40
antwortzeiten <- round(rnorm(n, mean = 185, sd = 28), 1)
# Datensatz als Tibble
api_daten <- tibble(
messung = 1:n,
antwortzeit_ms = antwortzeiten
)
```
::: {.callout-tip title="Lernziele"}
# Lernziele
Nach diesem Kapitel …
- **kann ich erklären**, was Null- und Alternativhypothese sind und wie ich sie für eine konkrete Fragestellung formuliere.
- **bin ich in der Lage**, die beiden Arten von Entscheidungsfehlern (Fehler 1. Art und Fehler 2. Art) zu benennen, zu unterscheiden und in einem realen Kontext zu interpretieren.
- **kann ich** die Begriffe Signifikanzniveau $\alpha$, Teststatistik und kritischer Bereich inhaltlich erläutern und rechnerisch anwenden.
- **bin ich in der Lage**, den p-Wert zu berechnen, grafisch zu interpretieren und korrekt in Worte zu fassen – ohne die häufigen Fehlinterpretationen.
- **kann ich** einen Einstichproben-t-Test bei unbekannter Varianz vollständig durchführen: von der Hypothesenformulierung über die Berechnung bis zur inhaltlichen Schlussfolgerung.
- **bin ich in der Lage**, den Zweistichproben-t-Test (unverbunden) auf Mittelwertvergleiche anzuwenden und seine Voraussetzungen zu prüfen.
- **kann ich** einen Anteilswerttest (Binomialtest) korrekt einsetzen, wenn die Zielgrösse eine Rate oder Quote ist.
- **kann ich** den Zusammenhang zwischen Hypothesentest und Konfidenzintervall erklären und als alternative Entscheidungsregel nutzen.
:::
Wir wollen in diesem Tutorial den statistischen Hypothesentest von der Grundidee bis zur praktischen Anwendung in R verstehen.
Der Einstieg ist bewusst konzeptuell: Bevor wir eine einzige Funktion aufrufen, klären wir, **was es eigentlich bedeutet, eine Hypothese zu «testen» – und welchen Preis wir für jede Entscheidung zahlen**.
Erst danach formalisieren wir das Vorgehen und wenden es auf ein durchgehendes Praxisbeispiel an.
---
# Die Herausforderung: Entscheiden unter Unsicherheit
Ein SaaS-Unternehmen betreibt einen REST-API-Dienst für seine Unternehmenskunden.
Im vertraglich festgelegten Service-Level-Agreement (SLA) wurde als Zielwert eine mittlere Antwortzeit von maximal **200 ms** vereinbart.
Nach einem aufwändigen Refactoring der Microservice-Architektur behauptet das Entwicklungsteam: *«Unsere neue Architektur ist schneller – die mittlere Antwortzeit liegt nun deutlich unter 200 ms.»*
Um diese Behauptung zu überprüfen, werden $n = 40$ Antwortzeiten gemessen.
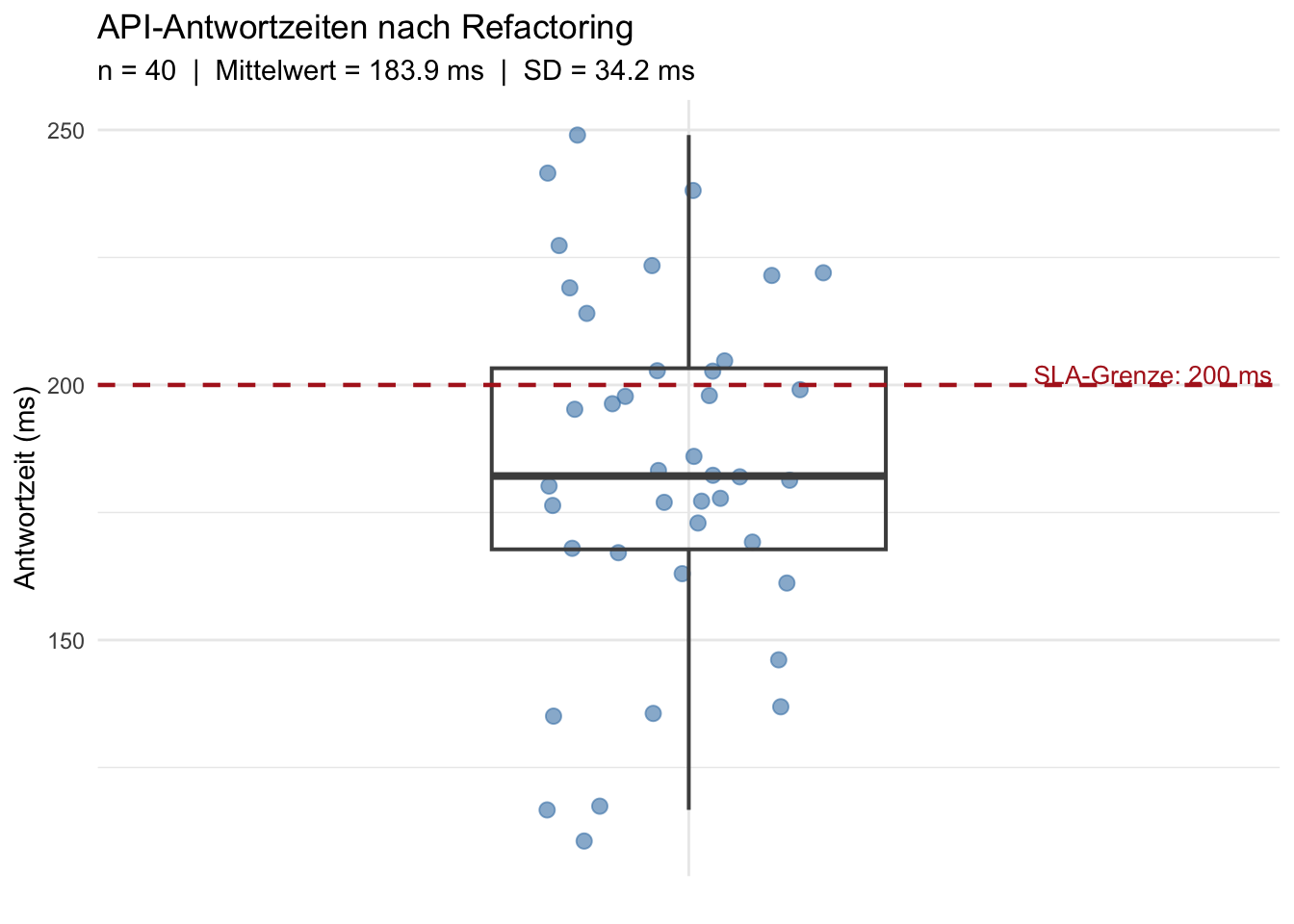
Wir visualisieren die Stichprobe:
```{r}
#| label: fig-motivation-boxplot
#| fig-cap: "Verteilung der gemessenen API-Antwortzeiten nach dem Refactoring (n = 40). Die gestrichelte Linie markiert den SLA-Grenzwert von 200 ms."
ggplot(api_daten, aes(x = "", y = antwortzeit_ms)) +
geom_jitter(color = "steelblue", alpha = 0.6, width = 0.15, size = 2.5) +
geom_boxplot(fill = NA, color = "grey30", linewidth = 0.7,
outlier.shape = NA, width = 0.4) +
geom_hline(yintercept = 200, linetype = "dashed",
color = "firebrick", linewidth = 0.8) +
annotate("text", x = 1.35, y = 202,
label = "SLA-Grenze: 200 ms",
color = "firebrick", size = 3.5, hjust = 0) +
labs(x = NULL, y = "Antwortzeit (ms)",
title = "API-Antwortzeiten nach Refactoring",
subtitle = paste0("n = ", nrow(api_daten),
" | Mittelwert = ",
round(mean(api_daten$antwortzeit_ms), 1),
" ms | SD = ",
round(sd(api_daten$antwortzeit_ms), 1), " ms")) +
theme_minimal()
```
Der Stichprobenmittelwert liegt bei `r round(mean(api_daten$antwortzeit_ms), 1)` ms – also unter 200 ms.
Aber: Könnte diese Abweichung auch zufällig entstanden sein, wenn der wahre Mittelwert gar nicht gesunken ist?
::: {.border-start .border-5 .border-success .ps-3 .ms-2}
*Wir haben 40 Messungen, deren Mittelwert unter 200 ms liegt – aber Stichproben schwanken. Ist der Unterschied «echt», oder sehen wir nur zufälliges Rauschen? Wie treffen wir eine objektive, nachvollziehbare Entscheidung?*
:::
Das ist die Kernfrage des statistischen Hypothesentests.
Wir brauchen ein **formales Entscheidungsverfahren**, das uns erlaubt, zwischen einem echten Effekt und zufälliger Schwankung zu unterscheiden.
---
# Hypothesen: Was testen wir eigentlich?
## Null- und Alternativhypothese
Jeder Hypothesentest beginnt mit der Formulierung von genau **zwei Hypothesen**, die sich gegenseitig ausschliessen.
Die **Nullhypothese** $H_0$ ist die «Skepsis-Hypothese»: Sie beschreibt den Zustand, den wir *widerlegen* wollen – typischerweise «kein Effekt» oder «kein Unterschied».
In unserem Beispiel: Die neue Architektur hat nichts verbessert, der wahre Mittelwert $\mu$ liegt noch bei 200 ms oder darüber.
Die **Alternativhypothese** $H_1$ (oder $H_A$) ist die «Forschungshypothese»: Sie beschreibt den Effekt, für den wir statistische Evidenz suchen.
::: {.callout-note}
### Theorie-Check
Lesen Sie im Lehrbuch (Mittag, Kap. 9) nach: Warum suchen wir Evidenz gegen die Nullhypothese, statt die Null- oder Alternativhypothese zu beweisen?
Was hat das mit dem Prinzip der Falsifizierbarkeit (Popper) zu tun?
(Stichwort: Beweislastumkehr, Unschuldsvermutung).
:::
## Drei Testrichtungen
Je nach Fragestellung unterscheiden wir drei Formen:
| Testtyp | Formulierung | Wann? |
|---|---|---|
| Linksseitiger Test | $H_0: \mu \geq \mu_0$ vs. $H_1: \mu < \mu_0$ | Prüfung auf «kleiner als» |
| Rechtsseitiger Test | $H_0: \mu \leq \mu_0$ vs. $H_1: \mu > \mu_0$ | Prüfung auf «grösser als» |
| Zweiseitiger Test | $H_0: \mu = \mu_0$ vs. $H_1: \mu \neq \mu_0$ | Prüfung auf «verschieden» |
Für unser API-Beispiel lautet die Frage: *Ist die mittlere Antwortzeit signifikant kleiner als 200 ms?*
Das ist ein **linksseitiger Test**:
$$H_0: \mu \geq 200 \text{ ms} \qquad \text{vs.} \qquad H_1: \mu < 200 \text{ ms}$$
::: {.callout-important}
## Hypothesen immer vor der Datensichtung formulieren!
Die Hypothesen müssen **vor** dem Blick in die Daten festgelegt werden.
Werden sie nachträglich an die Daten angepasst («HARKing»: Hypothesizing After Results are Known), ist das Ergebnis wertlos.
In unserem Beispiel wurde die Richtung des Tests durch das SLA und die Aussage des Entwicklungsteams vorgegeben – nicht durch den gemessenen Mittelwert.
:::
---
# Entscheidungsfehler: Was kann schiefgehen?
Ein Hypothesentest ist ein binäres Entscheidungsverfahren: Wir lehnen $H_0$ ab oder nicht.
Da wir mit einer Stichprobe arbeiten, können wir zwei Arten von Fehlern begehen.
## Die Fehlertabelle
| | $H_0$ ist wahr | $H_0$ ist falsch |
|---|---|---|
| **Entscheidung: $H_0$ ablehnen** | Fehler 1. Art ($\alpha$) | Richtige Entscheidung (Trennschärfe $1-\beta$) |
| **Entscheidung: $H_0$ nicht ablehnen** | Richtige Entscheidung | Fehler 2. Art ($\beta$) |
Der **Fehler 1. Art** (Typ-I-Fehler, $\alpha$) tritt auf, wenn wir $H_0$ ablehnen, obwohl sie wahr ist – also ein Effekt «gesehen» wird, der gar nicht existiert.
Im API-Beispiel: Wir schliessen fälschlich, die neue Architektur sei schneller, obwohl sich nichts verbessert hat.
Der **Fehler 2. Art** (Typ-II-Fehler, $\beta$) tritt auf, wenn wir $H_0$ *nicht* ablehnen, obwohl sie falsch ist – ein echter Effekt bleibt unentdeckt.
Im API-Beispiel: Die Architektur ist tatsächlich schneller, aber wir erkennen das nicht.
## Das Signifikanzniveau $\alpha$
Das **Signifikanzniveau** $\alpha$ ist die maximale Wahrscheinlichkeit, die wir für den Fehler 1. Art akzeptieren.
Es wird *vor* dem Test festgelegt und beantwortet die Frage: «Wie oft darf ich in 100 Tests fälschlicherweise $H_0$ ablehnen?»
Übliche Werte sind $\alpha = 0.05$ (5 %) oder $\alpha = 0.01$ (1 %).
Im SLA-Kontext wählen wir $\alpha = 0.05$: Wir akzeptieren ein 5-%-Risiko, die alte Architektur zu verwerfen, obwohl sie gleich geblieben ist.
::: {.callout-note}
### Theorie-Check
Lesen Sie im Lehrbuch (Mittag, Kap. 9.2) nach: Warum kann man $\alpha$ und $\beta$ nicht gleichzeitig beliebig klein machen?
Was ist die **Macht** (Power) $1 - \beta$ eines Tests, und wovon hängt sie ab?
(Stichwort: Stichprobengrösse, Effektgrösse, $\alpha$).
:::
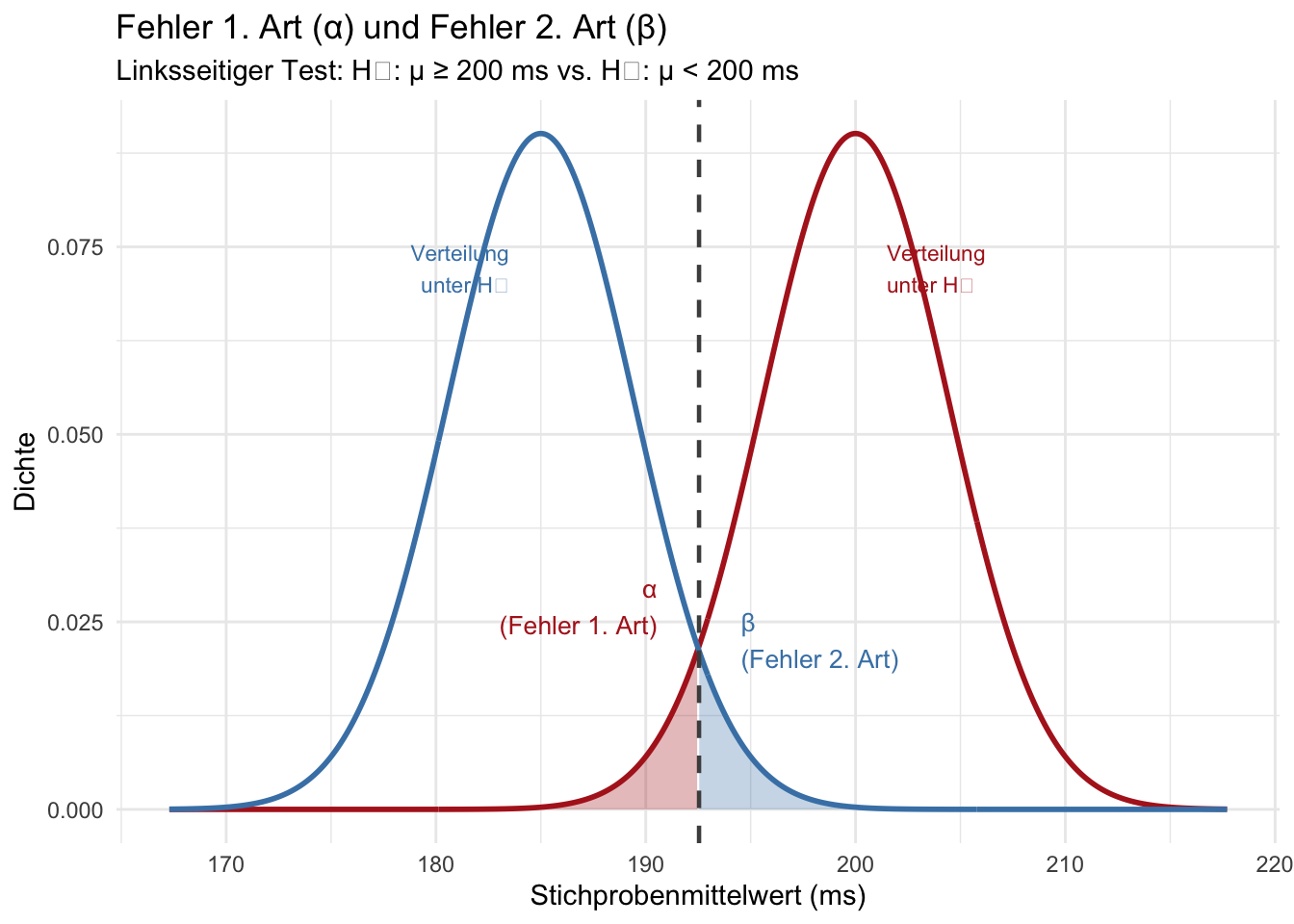
Die folgende Grafik ist eine **schematische Normalapproximation für den Stichprobenmittelwert**.
Sie zeigt nicht die t-Verteilung der Teststatistik, sondern veranschaulicht die Lage der Verteilungen unter einem Randfall von $H_0$ und einem beispielhaften Wert unter $H_1$.
Die blau markierte Wahrscheinlichkeit $\beta$ hängt vom konkreten wahren Mittelwert unter $H_1$ ab; hier wird beispielhaft $\mu_1 = 185$ ms verwendet.
```{r}
#| label: fig-fehlertypen
#| fig-cap: "Schematische Visualisierung der beiden Fehlertypen beim linksseitigen Test auf der Skala des Stichprobenmittelwerts. Die rote Fläche (α) ist der Ablehnbereich beim Randfall von H₀. Die blaue Fläche (β) ist die Wahrscheinlichkeit, bei einem beispielhaften wahren Mittelwert von 185 ms einen echten Effekt zu übersehen."
mu_0 <- 200 # Nullhypothese
mu_1 <- 185 # hypothetischer wahrer Wert unter H1
sigma <- 28 / sqrt(40) # Standardfehler
x <- seq(mu_1 - 4 * sigma, mu_0 + 4 * sigma, length.out = 500)
t_krit <- mu_0 + qt(0.05, df = 39) * sigma # kritischer Wert
df_plot <- tibble(
x = x,
dichte_H0 = dnorm(x, mean = mu_0, sd = sigma),
dichte_H1 = dnorm(x, mean = mu_1, sd = sigma)
)
ggplot(df_plot, aes(x)) +
# H0-Verteilung
geom_line(aes(y = dichte_H0), color = "firebrick", linewidth = 1) +
geom_area(data = filter(df_plot, x <= t_krit),
aes(y = dichte_H0), fill = "firebrick", alpha = 0.3) +
# H1-Verteilung
geom_line(aes(y = dichte_H1), color = "steelblue", linewidth = 1) +
geom_area(data = filter(df_plot, x >= t_krit),
aes(y = dichte_H1), fill = "steelblue", alpha = 0.3) +
# Kritische Grenze
geom_vline(xintercept = t_krit, linetype = "dashed",
color = "grey30", linewidth = 0.8) +
# Beschriftungen
annotate("text", x = t_krit - 2, y = max(df_plot$dichte_H0) * 0.3,
label = "α\n(Fehler 1. Art)", color = "firebrick",
size = 3.5, hjust = 1) +
annotate("text", x = t_krit + 2, y = max(df_plot$dichte_H1) * 0.25,
label = "β\n(Fehler 2. Art)", color = "steelblue",
size = 3.5, hjust = 0) +
annotate("text", x = mu_0 + 1.5, y = max(df_plot$dichte_H0) * 0.8,
label = "Verteilung\nunter H₀", color = "firebrick",
size = 3, hjust = 0) +
annotate("text", x = mu_1 - 1.5, y = max(df_plot$dichte_H1) * 0.8,
label = "Verteilung\nunter H₁", color = "steelblue",
size = 3, hjust = 1) +
labs(x = "Stichprobenmittelwert (ms)", y = "Dichte",
title = "Fehler 1. Art (α) und Fehler 2. Art (β)",
subtitle = "Linksseitiger Test: H₀: μ ≥ 200 ms vs. H₁: μ < 200 ms") +
theme_minimal()
```
---
# Die Teststatistik und der kritische Bereich
## Vom Stichprobenmittelwert zur Teststatistik
Um zu entscheiden, ob unser Stichprobenmittelwert $\bar{x}$ «weit genug» von $\mu_0 = 200$ ms entfernt liegt, müssen wir ihn **standardisieren**: Wie viele Standardfehler liegt $\bar{x}$ vom Hypothesenwert entfernt?
Da die wahre Varianz $\sigma^2$ unbekannt ist (der Normalfall in der Praxis), schätzen wir sie durch die Stichprobenvarianz $s^2$ und erhalten den **t-Wert**:
$$t = \frac{\bar{x} - \mu_0}{s / \sqrt{n}}$$
Für die Berechnung verwenden wir den **Randfall** der Nullhypothese, also $\mu = \mu_0 = 200$ ms.
Unter diesem Randfall folgt diese Statistik einer **t-Verteilung** mit $n - 1 = 39$ Freiheitsgraden.
Für Werte $\mu > 200$ ms wäre die Ablehnwahrscheinlichkeit beim linksseitigen Test kleiner; der Randfall ist daher für den Fehler 1. Art der kritische Fall.
::: {.callout-note}
### Theorie-Check
Lesen Sie im Lehrbuch (Mittag, Kap. 8.3) nach: Warum verwenden wir bei unbekanntem $\sigma$ die t-Verteilung und nicht die Standardnormalverteilung?
Was passiert mit der t-Verteilung, wenn $n \to \infty$?
(Stichwort: Student-Verteilung, Freiheitsgrade, Schätzunsicherheit für $\sigma$).
:::
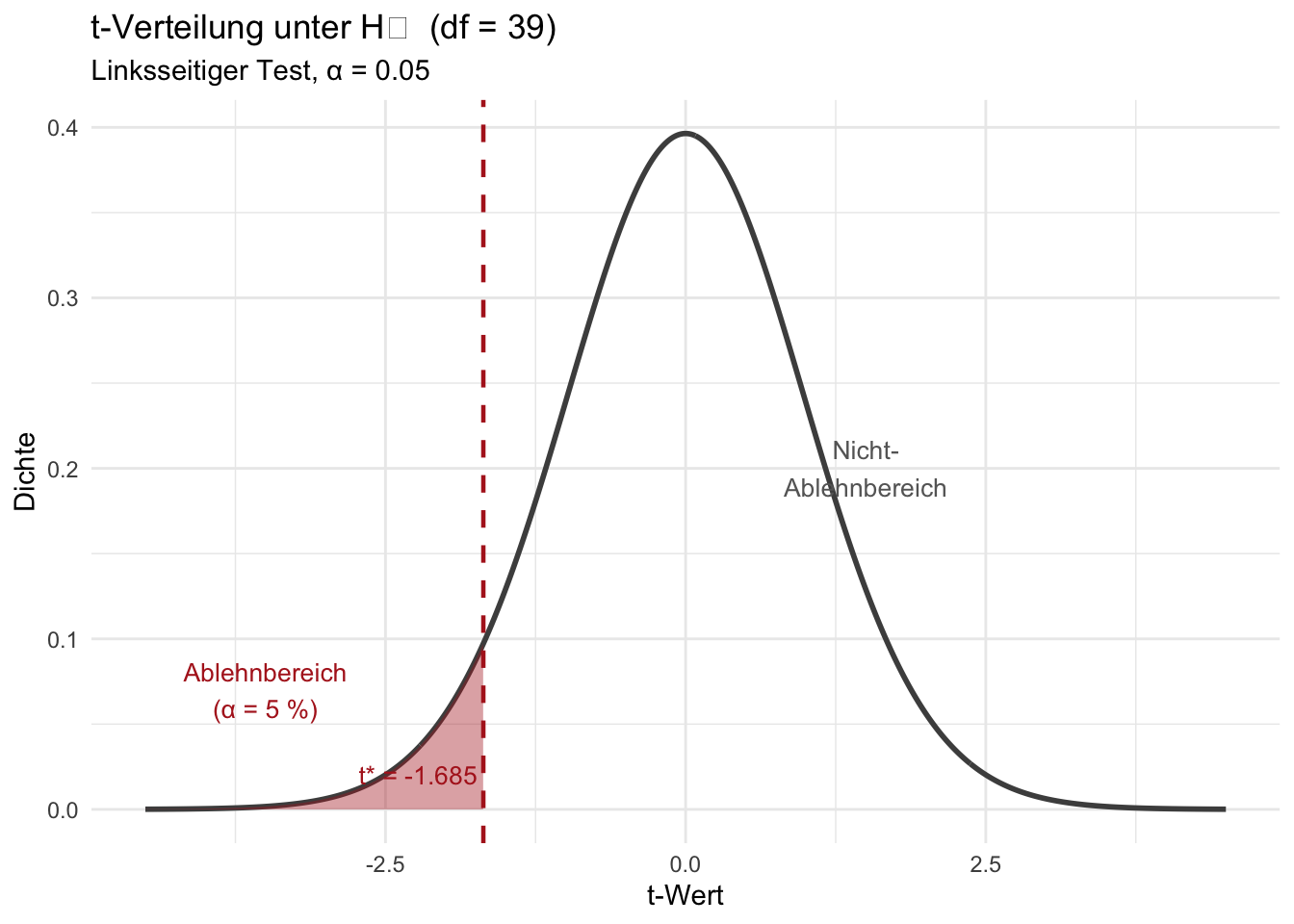
## Der kritische Bereich
Der **kritische Bereich** $K$ ist die Menge aller Stichprobenergebnisse, bei denen wir $H_0$ ablehnen.
Beim linksseitigen Test zum Niveau $\alpha = 0.05$ gilt:
$$K = \left\{ t \;\Big|\; t < t_{n-1;\, \alpha} \right\} = \left\{ t \;\Big|\; t < t_{39;\, 0.05} \right\}$$
Den kritischen t-Wert liefert in R die Funktion `qt()`:
```{r}
#| label: kritischer-wert
alpha <- 0.05
n <- 40
df <- n - 1
t_krit_wert <- qt(alpha, df = df)
cat("Kritischer t-Wert (linksseitig, α = 0.05, df = 39):", round(t_krit_wert, 4), "\n")
```
Wir lehnen $H_0$ ab, wenn der berechnete t-Wert kleiner als `r round(qt(0.05, 39), 3)` ist.
```{r}
#| label: fig-kritischer-bereich
#| fig-cap: "Die t-Verteilung unter H₀ (df = 39). Der rote Ablehnbereich liegt links vom kritischen Wert t* ≈ −1.685. Liegt die berechnete Teststatistik in diesem Bereich, verwerfen wir H₀."
x_t <- seq(-4.5, 4.5, length.out = 500)
df_t <- tibble(x = x_t, y = dt(x, df = 39))
t_star <- qt(0.05, df = 39)
ggplot(df_t, aes(x, y)) +
geom_line(color = "grey30", linewidth = 1) +
geom_area(data = filter(df_t, x <= t_star),
fill = "firebrick", alpha = 0.4) +
geom_vline(xintercept = t_star, linetype = "dashed",
color = "firebrick", linewidth = 0.8) +
annotate("text", x = t_star - 0.05, y = 0.02,
label = paste0("t* = ", round(t_star, 3)),
color = "firebrick", size = 3.5, hjust = 1) +
annotate("text", x = -3.5, y = 0.07,
label = "Ablehnbereich\n(α = 5 %)",
color = "firebrick", size = 3.5) +
annotate("text", x = 1.5, y = 0.2,
label = "Nicht-\nAblehnbereich",
color = "grey40", size = 3.5) +
labs(x = "t-Wert", y = "Dichte",
title = "t-Verteilung unter H₀ (df = 39)",
subtitle = "Linksseitiger Test, α = 0.05") +
theme_minimal()
```
---
# Der p-Wert: Eine andere Sprache für dasselbe Konzept
## Definition und Berechnung
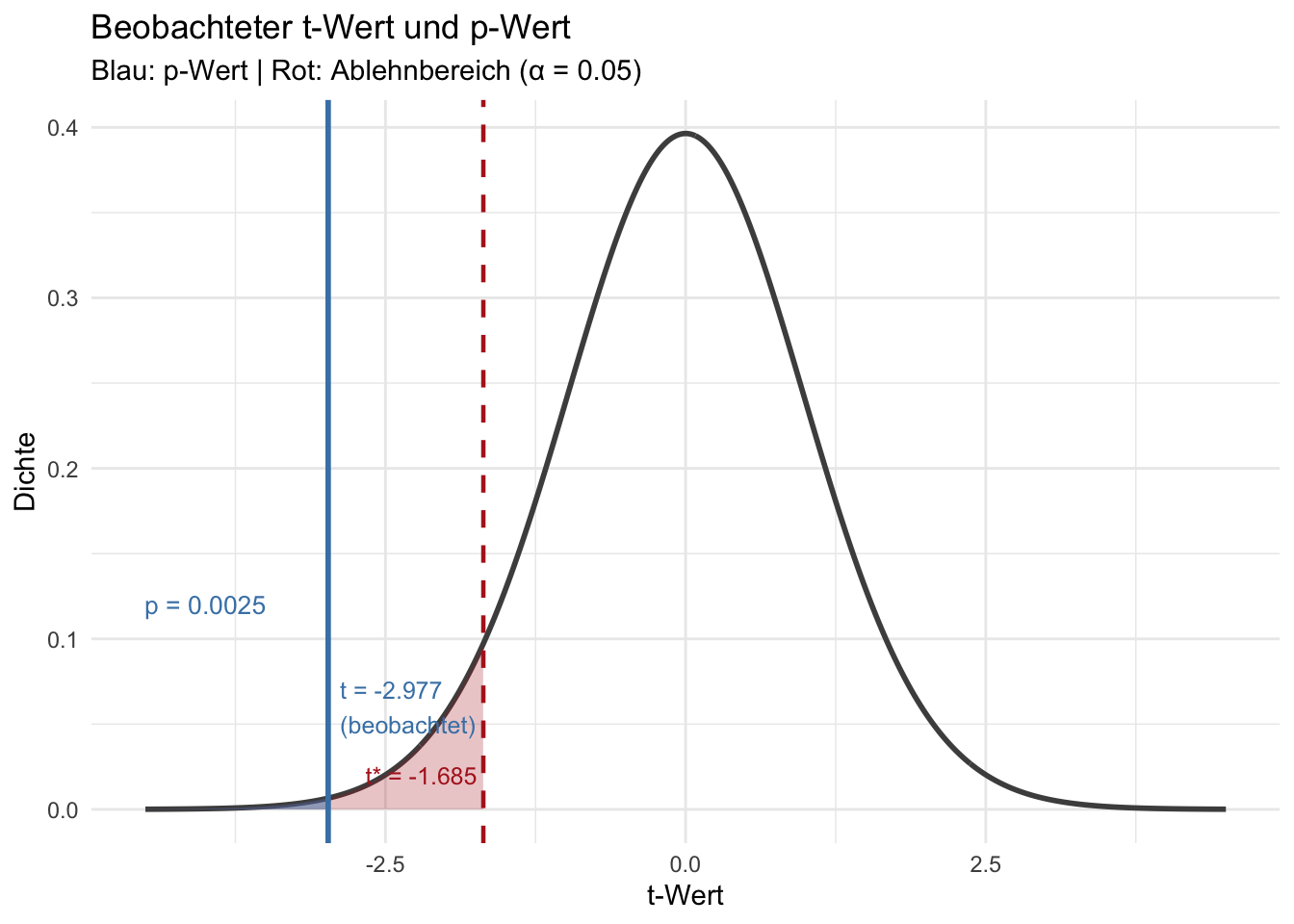
Der **p-Wert** ist die Wahrscheinlichkeit, unter der Nullhypothese ein Testergebnis zu erhalten, das *mindestens so extrem* ist wie das beobachtete.
Formal:
$$p\text{-Wert} = P(T \leq t_{\text{beobachtet}} \mid H_0 \text{ wahr})$$
Je kleiner der p-Wert, desto **unvereinbarer** ist das Ergebnis mit $H_0$.
Die Entscheidungsregel lautet:
- $p\text{-Wert} \leq \alpha$ → $H_0$ ablehnen
- $p\text{-Wert} > \alpha$ → $H_0$ nicht ablehnen
```{r}
#| label: t-test-manuell
x_bar <- mean(api_daten$antwortzeit_ms)
s <- sd(api_daten$antwortzeit_ms)
n <- nrow(api_daten)
mu_0 <- 200
# Teststatistik
t_beob <- (x_bar - mu_0) / (s / sqrt(n))
# p-Wert (linksseitiger Test)
p_wert <- pt(t_beob, df = n - 1)
cat("Stichprobenmittelwert:", round(x_bar, 2), "ms\n")
cat("Stichproben-SD: ", round(s, 2), "ms\n")
cat("Standardfehler: ", round(s / sqrt(n), 3), "ms\n")
cat("Teststatistik t: ", round(t_beob, 4), "\n")
cat("p-Wert: ", round(p_wert, 4), "\n")
cat("Kritischer t-Wert: ", round(qt(0.05, df = n - 1), 4), "\n")
```
```{r}
#| label: fig-p-wert
#| fig-cap: "Die beobachtete Teststatistik (blauer Pfeil) und der zugehörige p-Wert (blaue Fläche) unter der t-Verteilung bei wahrer H₀. Liegt die blaue Fläche innerhalb des roten Ablehnbereichs, wird H₀ verworfen."
t_obs <- (mean(api_daten$antwortzeit_ms) - 200) /
(sd(api_daten$antwortzeit_ms) / sqrt(40))
df_t2 <- tibble(x = x_t, y = dt(x, df = 39))
ggplot(df_t2, aes(x, y)) +
geom_line(color = "grey30", linewidth = 1) +
geom_area(data = filter(df_t2, x <= t_star),
fill = "firebrick", alpha = 0.25) +
geom_area(data = filter(df_t2, x <= t_obs),
fill = "steelblue", alpha = 0.5) +
geom_vline(xintercept = t_star, linetype = "dashed",
color = "firebrick", linewidth = 0.8) +
geom_vline(xintercept = t_obs, color = "steelblue", linewidth = 1) +
annotate("text", x = t_star - 0.05, y = 0.02,
label = paste0("t* = ", round(t_star, 3)),
color = "firebrick", size = 3.3, hjust = 1) +
annotate("text", x = t_obs + 0.1, y = 0.06,
label = paste0("t = ", round(t_obs, 3), "\n(beobachtet)"),
color = "steelblue", size = 3.3, hjust = 0) +
annotate("text", x = -4, y = 0.12,
label = paste0("p = ", round(pt(t_obs, 39), 4)),
color = "steelblue", size = 3.5) +
labs(x = "t-Wert", y = "Dichte",
title = "Beobachteter t-Wert und p-Wert",
subtitle = "Blau: p-Wert | Rot: Ablehnbereich (α = 0.05)") +
theme_minimal()
```
## Häufige Fehlinterpretationen des p-Werts
::: {.callout-important}
## Was der p-Wert NICHT ist
Der p-Wert wird in der Praxis häufig falsch interpretiert.
Die folgenden Aussagen sind **falsch**:
- *«Der p-Wert ist die Wahrscheinlichkeit, dass H₀ wahr ist.»*
→ Falsch. H₀ ist entweder wahr oder falsch – keine Wahrscheinlichkeit.
- *«Ein p-Wert < 0.05 beweist, dass H₁ wahr ist.»*
→ Falsch. Er zeigt nur, dass die Daten unter H₀ unwahrscheinlich wären.
- *«Ein kleiner p-Wert bedeutet einen grossen Effekt.»*
→ Falsch. Bei grossem $n$ können triviale Unterschiede hochsignifikant werden.
**Richtig:** Der p-Wert ist die Wahrscheinlichkeit, unter H₀ ein Testergebnis zu beobachten, das mindestens so extrem ist wie das tatsächlich beobachtete.
:::
---
# Der Einstichproben-t-Test in R
## Vollständige Durchführung
In R erledigt `t.test()` den gesamten Test in einer Zeile.
Wir führen den linksseitigen Test durch ($H_1: \mu < 200$ ms):
```{r}
#| label: t-test-r
ergebnis <- t.test(
api_daten$antwortzeit_ms,
mu = 200,
alternative = "less", # linksseitiger Test
conf.level = 0.95
)
ergebnis
```
## Interpretation der Ausgabe
Aus der Ausgabe lesen wir ab:
- **t = `r round(ergebnis$statistic, 3)`**, df = 39: Die beobachtete Teststatistik liegt bei `r round(ergebnis$statistic, 3)` Standardfehlern unter dem Hypothesenwert.
- **p-Wert = `r round(ergebnis$p.value, 4)`**: Da $p < 0.05$, lehnen wir $H_0$ zum Niveau $\alpha = 0.05$ ab.
- **95-%-Konfidenzintervall**: Das einseitige KI $(-\infty,\, `r round(ergebnis$conf.int[2], 1)`)$ ms enthält den Wert 200 ms nicht – konsistente Schlussfolgerung.
::: {.border-start .border-5 .border-success .ps-3 .ms-2}
*Wir haben statistisch signifikante Evidenz dafür, dass die mittlere Antwortzeit nach dem Refactoring unter 200 ms liegt ($t = $ `r round(ergebnis$statistic, 2)`, $df = 39$, $p = $ `r round(ergebnis$p.value, 3)`, $\alpha = 0.05$). Unter den Modellannahmen spricht die Stichprobe somit dafür, dass das SLA-Ziel bezüglich der mittleren Antwortzeit eingehalten wird. Der gemessene Mittelwert von `r round(mean(api_daten$antwortzeit_ms), 1)` ms liegt dabei rund `r round(200 - mean(api_daten$antwortzeit_ms), 1)` ms unterhalb der Grenze.*
:::
---
# Der Zweistichproben-t-Test: Vergleich zweier Architekturen
## Fragestellung
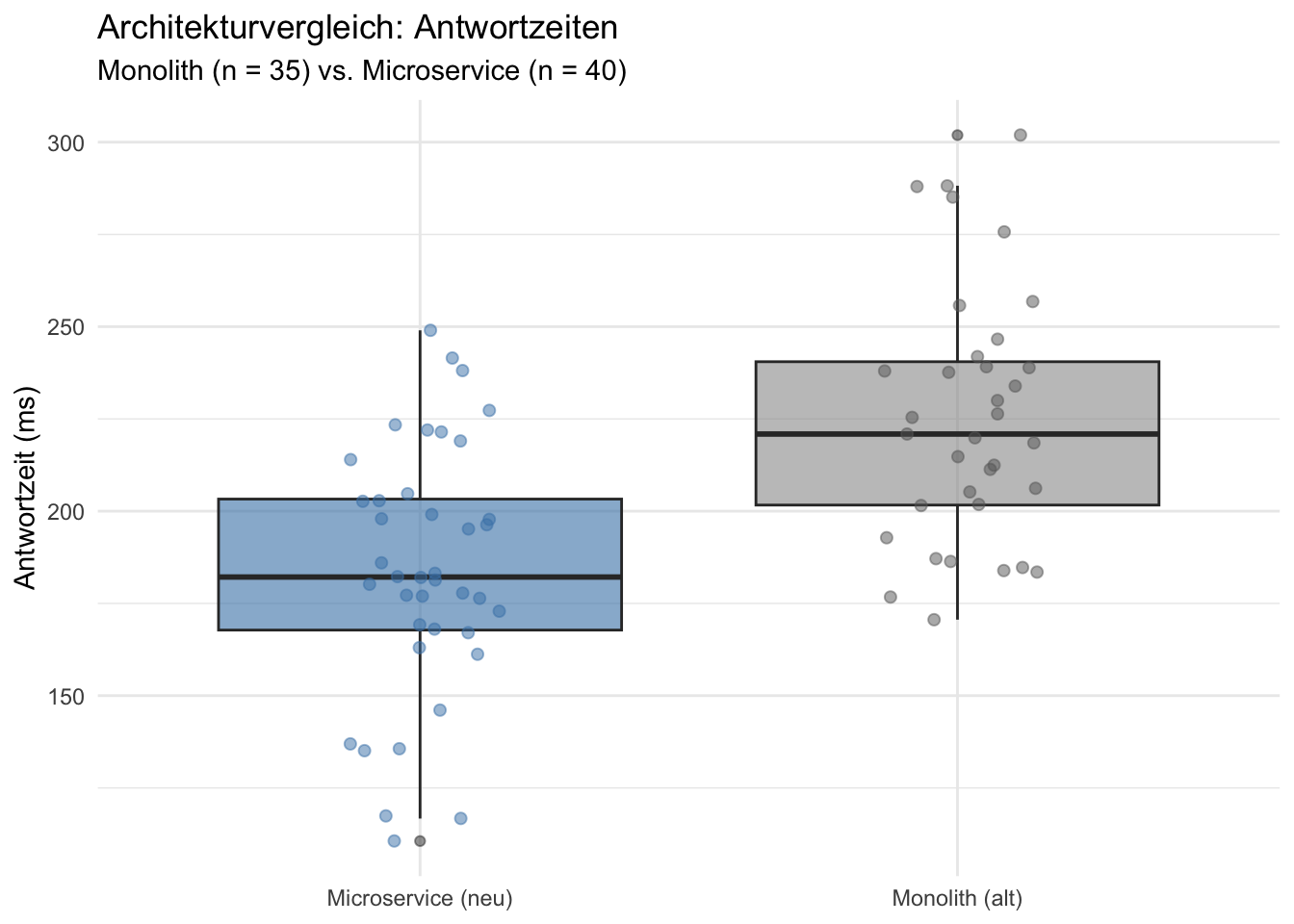
Nehmen wir an, wir wollen die neue Microservice-Architektur **direkt mit der alten Monolith-Architektur vergleichen**.
Dazu liegen uns $n_{\text{alt}} = 35$ historische Messungen der alten Architektur vor.
```{r}
#| label: zweistichproben-daten
set.seed(7)
alt_architektur <- tibble(
architektur = "Monolith (alt)",
antwortzeit_ms = round(rnorm(35, mean = 215, sd = 32), 1)
)
neu_architektur <- tibble(
architektur = "Microservice (neu)",
antwortzeit_ms = api_daten$antwortzeit_ms
)
vergleich <- bind_rows(alt_architektur, neu_architektur)
```
Die Hypothesen lauten jetzt:
$$H_0: \mu_{\text{neu}} \geq \mu_{\text{alt}} \qquad \text{vs.} \qquad H_1: \mu_{\text{neu}} < \mu_{\text{alt}}$$
Für die Berechnung des p-Werts wird beim gerichteten Welch-Test der Randfall $\mu_{\text{neu}} = \mu_{\text{alt}}$ betrachtet.
```{r}
#| label: fig-zweistichproben
#| fig-cap: "Vergleich der Antwortzeiten für alte und neue Architektur. Die Boxplots zeigen Median, Quartile und Streuung."
ggplot(vergleich, aes(x = architektur, y = antwortzeit_ms, fill = architektur)) +
geom_boxplot(alpha = 0.6, outlier.alpha = 0.5) +
geom_jitter(aes(color = architektur), width = 0.15,
alpha = 0.5, size = 1.8) +
scale_fill_manual(values = c("Monolith (alt)" = "grey60",
"Microservice (neu)" = "steelblue")) +
scale_color_manual(values = c("Monolith (alt)" = "grey40",
"Microservice (neu)" = "steelblue")) +
labs(x = NULL, y = "Antwortzeit (ms)",
title = "Architekturvergleich: Antwortzeiten",
subtitle = "Monolith (n = 35) vs. Microservice (n = 40)") +
theme_minimal() +
theme(legend.position = "none")
```
## Durchführung und Voraussetzungen
Beim **unverbundenen Zweistichproben-t-Test** (Welch-Test) müssen die beiden Gruppen unabhängig voneinander sein.
Die Annahme gleicher Varianzen (Homoskedastizität) ist **nicht erforderlich** – R verwendet standardmässig die Welch-Korrektur für die Freiheitsgrade.
```{r}
#| label: zweistichproben-test
ergebnis_2 <- t.test(
x = neu_architektur$antwortzeit_ms,
y = alt_architektur$antwortzeit_ms,
alternative = "less", # neu < alt
conf.level = 0.95,
var.equal = FALSE # Welch-Test (Standardeinstellung)
)
ergebnis_2
```
::: {.callout-note}
### Theorie-Check
Lesen Sie im Lehrbuch (Mittag, Kap. 9.4) nach: Was ist der Unterschied zwischen dem klassischen t-Test (gleiche Varianzen) und dem Welch-Test?
Wann ist der Welch-Test vorzuziehen, und welche Konsequenz hat die Welch-Korrektur für die Freiheitsgrade?
(Stichwort: Satterthwaite-Approximation).
:::
---
# Der Anteilswerttest: Fehlerquoten überwachen
## Fragestellung
Neben der Antwortzeit ist die **Fehlerquote** (Anteil der Anfragen mit HTTP-5xx-Fehler) ein kritischer KPI.
Das SLA schreibt vor: Maximal 3 % der Anfragen dürfen fehlerhaft sein.
In einer Stichprobe von $n = 500$ zufällig gewählten Anfragen wurden $x = 22$ Fehler gezählt.
Gibt es statistische Evidenz dafür, dass die Fehlerquote die SLA-Grenze überschreitet?
$$H_0: p \leq 0.03 \qquad \text{vs.} \qquad H_1: p > 0.03$$
Das ist ein **rechtsseitiger Test** auf den Anteilswert $p$.
Für die Berechnung des p-Werts wird der Randfall $p = 0.03$ betrachtet.
## Teststatistik beim Anteilswerttest
Beim Anteilswerttest wird die Teststatistik auf dem Normalapproximationsansatz oder dem exakten Binomialtest aufgebaut.
In R bieten sich zwei Varianten an:
```{r}
#| label: anteilswerttest
n_anfragen <- 500
n_fehler <- 22
p_0 <- 0.03 # SLA-Grenzwert
# Variante 1: Exakter Binomialtest (bevorzugt bei kleinen Stichproben)
binom_test <- binom.test(
x = n_fehler,
n = n_anfragen,
p = p_0,
alternative = "greater"
)
# Variante 2: Normalapproximation (prop.test, für grosse n geeignet)
prop_test <- prop.test(
x = n_fehler,
n = n_anfragen,
p = p_0,
alternative = "greater",
correct = FALSE
)
cat("=== Exakter Binomialtest ===\n")
cat("Beobachteter Anteil p̂ =", round(n_fehler / n_anfragen, 4), "\n")
cat("p-Wert:", round(binom_test$p.value, 4), "\n")
cat("95%-KI: [", round(binom_test$conf.int[1], 4), ",",
round(binom_test$conf.int[2], 4), "]\n\n")
cat("=== Normalapproximation (prop.test) ===\n")
cat("p-Wert:", round(prop_test$p.value, 4), "\n")
```
::: {.callout-note}
### Theorie-Check
Lesen Sie im Lehrbuch (Mittag, Kap. 9.5) nach: Wann ist die Normalapproximation für Anteilswerte gültig?
Warum empfiehlt sich `binom.test()` bei kleinen $n$ oder bei $p$-Werten nahe 0 oder 1?
(Stichwort: Faustregel $n \cdot p_0 \geq 5$ und $n \cdot (1 - p_0) \geq 5$).
:::
Mit einem p-Wert von `r round(binom_test$p.value, 4)` und $\alpha = 0.05$ liegt das Ergebnis knapp über dem Signifikanzniveau.
Wir können $H_0$ daher **nicht** ablehnen.
Die Stichprobe liefert keine ausreichende Evidenz dafür, dass die Fehlerquote die 3-%-Grenze überschreitet; sie beweist aber nicht, dass die Fehlerquote tatsächlich innerhalb der SLA-Grenze liegt.
---
# Zusammenhang: Hypothesentest und Konfidenzintervall
Hypothesentest und Konfidenzintervall sind zwei Seiten derselben Medaille.
::: {.callout-note}
## Äquivalenzprinzip
Beim zweiseitigen Test zum Niveau $\alpha$ gilt:
**$H_0: \mu = \mu_0$ wird abgelehnt $\iff$ $\mu_0$ liegt ausserhalb des $(1 - \alpha)$-Konfidenzintervalls.**
Beim einseitigen Test entspricht das Konfidenzintervall einem einseitigen Konfidenzband.
:::
```{r}
#| label: ki-aequivalenz
# Einstichproben-t-Test (zweiseitig) und zugehöriges 95%-KI
ki_ergebnis <- t.test(
api_daten$antwortzeit_ms,
mu = 200,
alternative = "two.sided",
conf.level = 0.95
)
cat("Zweiseitiger Test:\n")
cat("p-Wert:", round(ki_ergebnis$p.value, 4), "\n")
cat("95%-KI: [", round(ki_ergebnis$conf.int[1], 2), ",",
round(ki_ergebnis$conf.int[2], 2), "] ms\n")
cat("Enthält das KI den Wert 200?",
ifelse(ki_ergebnis$conf.int[1] <= 200 & 200 <= ki_ergebnis$conf.int[2],
"Ja → H₀ nicht ablehnen",
"Nein → H₀ ablehnen"), "\n")
```
Das 95-%-KI für den zweiseitigen Test enthält den Wert 200 ms in diesem Datensatz nicht.
Das ist konsistent damit, dass auch der zweiseitige Test $H_0: \mu = 200$ zum Niveau 0.05 abgelehnt wird.
Der linksseitige Test bleibt dennoch die passende Wahl, wenn die Fragestellung bereits vor der Datensichtung gerichtet formuliert wurde: $\mu < 200$ ms.
---
# Schnellreferenz: Welcher Test für welche Situation?
| Situation | Zielgrösse | Voraussetzung | R-Funktion |
|---|---|---|---|
| Eine Stichprobe, $\mu$ testen, $\sigma$ unbekannt | Mittelwert | unabhängige Beobachtungen; keine extremen Ausreisser; annähernde Normalverteilung oder ausreichend grosses $n$ | `t.test(x, mu = …)` |
| Zwei unabhängige Stichproben, $\mu_1$ vs. $\mu_2$ | Mittelwertdifferenz | unabhängige Gruppen und Beobachtungen; keine extremen Ausreisser; annähernde Normalverteilung oder ausreichend grosse Stichproben | `t.test(x, y, var.equal = FALSE)` |
| Zwei verbundene Stichproben (Vorher/Nachher) | Differenz der Paare | Paarbindung; Differenzen annähernd normalverteilt oder ausreichend viele Paare | `t.test(x, y, paired = TRUE)` |
| Ein Anteilswert $p$ testen | Anteil, Rate | feste Anzahl Versuche; unabhängige Bernoulli-Beobachtungen; konstante Erfolgswahrscheinlichkeit | `binom.test()` / `prop.test()` |
| Zwei Anteilswerte vergleichen | Anteilsdifferenz | unabhängige Bernoulli-Beobachtungen je Gruppe; bei Normalapproximation ausreichend grosse erwartete Häufigkeiten | `prop.test(c(x1, x2), c(n1, n2))` |
---
# Zusammenfassung
Wir haben den statistischen Hypothesentest von der Grundidee bis zur praktischen Anwendung entwickelt.
Die wichtigsten Erkenntnisse:
Die **Testlogik** folgt immer dem gleichen Schema: Hypothesen formulieren → Signifikanzniveau festlegen → Teststatistik berechnen → mit kritischem Bereich oder p-Wert entscheiden → inhaltlich interpretieren.
**$H_0$ wird nie «bewiesen»**, sondern nur abgelehnt oder nicht abgelehnt.
Der Fehler 2. Art (einen echten Effekt zu übersehen) ist genauso real wie der Fehler 1. Art – er wird nur seltener diskutiert.
Der **p-Wert** misst, wie unvereinbar die Daten mit $H_0$ sind, nicht die Wahrscheinlichkeit von $H_0$.
Statistisch signifikant bedeutet nicht automatisch praktisch bedeutsam – bei grossen Stichproben können triviale Unterschiede hochsignifikant werden.
Der **Einstichproben-t-Test** ist das Arbeitstier für Mittelwertvergleiche bei unbekannter Varianz.
Der **Welch-Zweistichproben-t-Test** erweitert ihn auf den Vergleich zweier unabhängiger Gruppen, ohne Gleichheit der Varianzen vorauszusetzen.
Der **Binomialtest** (oder `prop.test()` für grosse Stichproben) ist die richtige Wahl, wenn die Zielgrösse eine Rate oder ein Anteil ist.
**Hypothesentest und Konfidenzintervall** sind beim zweiseitigen Test äquivalent: Ein $(1 - \alpha)$-KI, das $\mu_0$ ausschliesst, entspricht exakt dem Ablehnen von $H_0$ zum Niveau $\alpha$.
---
# Anhang: Das vollständige Testablaufschema
```{r}
#| label: fig-testablauf
#| fig-cap: "Schematischer Ablauf eines statistischen Hypothesentests."
# Hinweis: Dieses Diagramm kann alternativ mit dem DiagrammeR-Paket
# oder als externe SVG-Grafik eingebunden werden.
# Hier zeigen wir ein einfaches Ablaufschema als Tabelle.
```
| Schritt | Aktion | Im API-Beispiel |
|---|---|---|
| **1. Hypothesen** | $H_0$ und $H_1$ formulieren | $H_0: \mu \geq 200$ ms; $H_1: \mu < 200$ ms |
| **2. Signifikanzniveau** | $\alpha$ festlegen (vor Datensichtung) | $\alpha = 0.05$ |
| **3. Teststatistik** | Berechnungsformel wählen | $t = (\bar{x} - \mu_0) / (s/\sqrt{n})$ |
| **4. Kritischer Bereich** | Ablehnbereich bestimmen | $t < t_{39;\, 0.05} = -1.685$ |
| **5. Berechnung** | Teststatistik aus Daten berechnen | `t.test(…, alternative = "less")` |
| **6. Entscheidung** | p-Wert $\leq \alpha$ oder $t \in K$? | $p = $ `r round(ergebnis$p.value, 3)` $< 0.05$ → $H_0$ ablehnen |
| **7. Interpretation** | Inhaltliche Schlussfolgerung | Signifikant schneller als 200 ms |
::: {.callout-note}
## Weiterführende Literatur
- **Mittag, H.-J.** (2021). *Statistik – Eine Einführung mit interaktiven Elementen*. Springer Gabler. Kapitel 9: Hypothesentests.
- **Dalgaard, P.** (2008). *Introductory Statistics with R*. Springer. Kapitel 5–6: t-Tests und Proportion-Tests in R.
- **Wasserstein, R. L. & Lazar, N. A.** (2016). The ASA's statement on p-values: context, process, and purpose. *The American Statistician*, 70(2), 129–133. – Empfehlenswert zur korrekten Interpretation des p-Werts.
:::